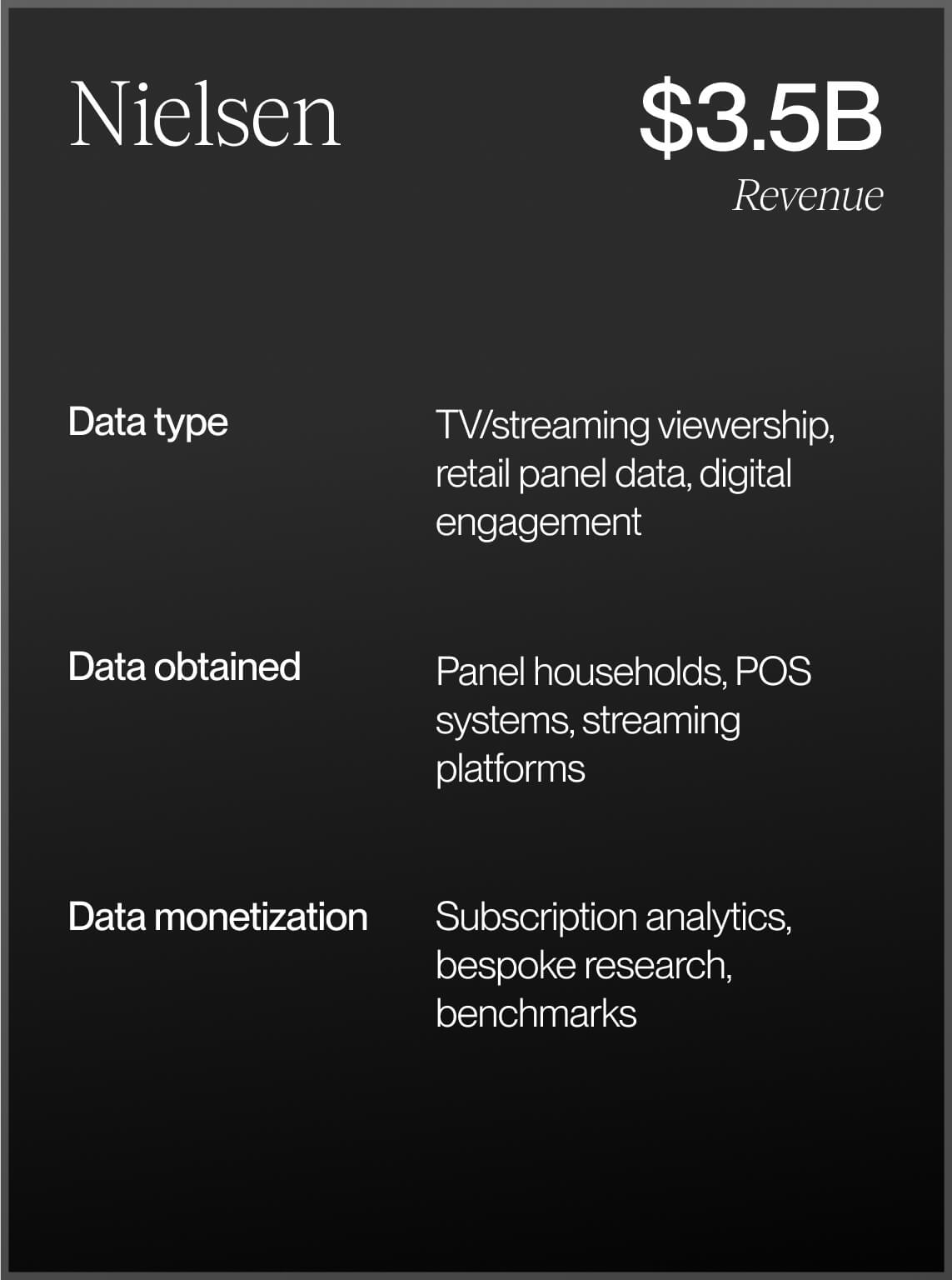
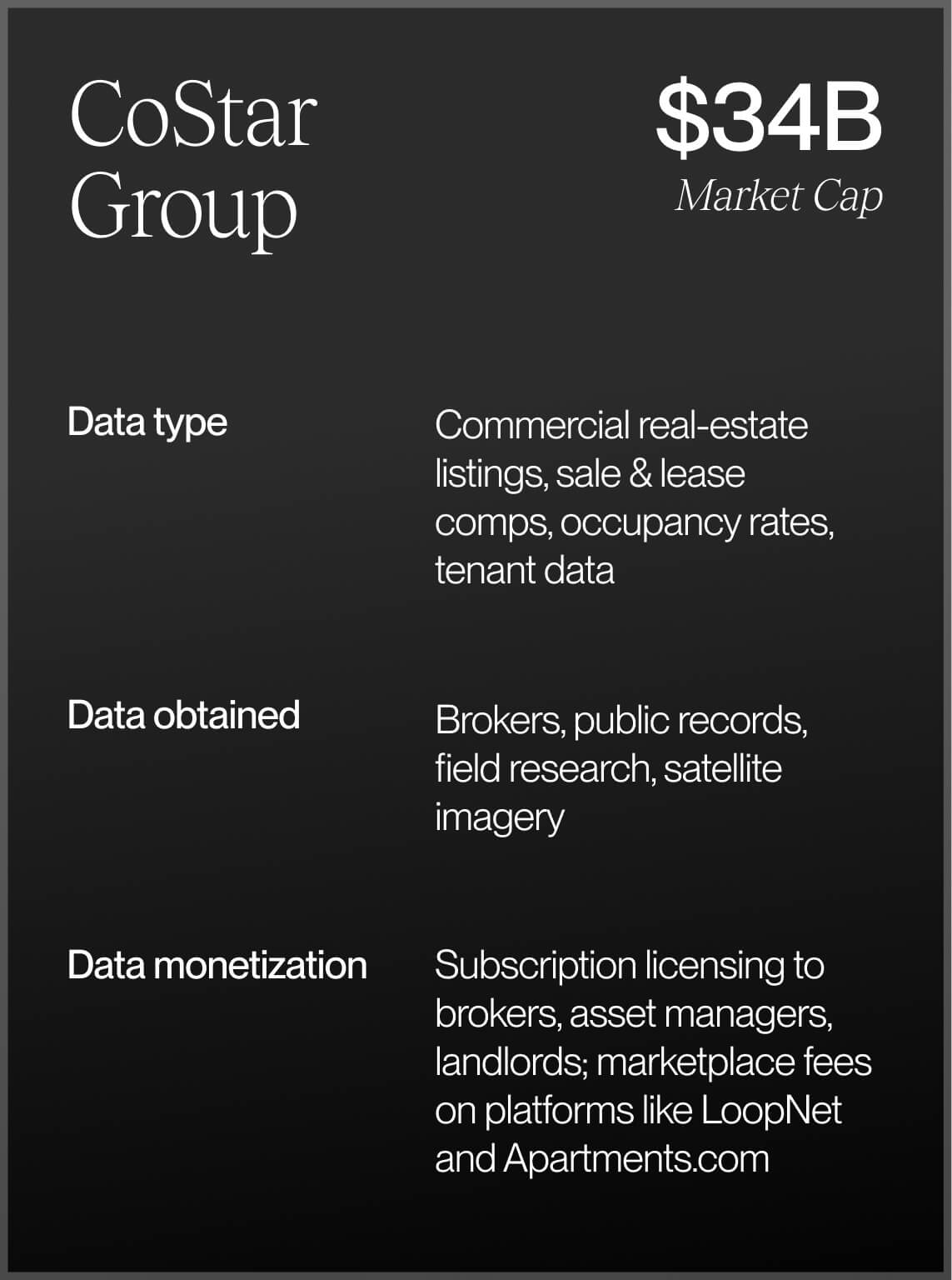
For decades, data monopolies have dominated entire markets by gatekeeping access to vital information. For examples, look toward the main credit bureaus: Equifax, TransUnion, Experian. Along credit lines, FICO scores can make or break job candidacies, financial instrument access and eligibility for customer-facing services from auto lending to home mortgage management. Outside of finance and fintech, consider Epic Systems, the EHR quasi-monopoly that holds 260 million individual patient records, representing just under 80% of the entire U.S. population. Take a closer look at companies that literally own most, if not all, of the data in their respective specialty areas like Dun & Bradstreet, regarded as the central source of American commercial data, or regulatory and legal data repository LexisNexis. Or LinkedIn, which has become the de facto source of truth for professional identity, aggregating an economic graph encompassing employment history, skills, and network connections for over a billion users.
The problem is not that these businesses become dominant (as a VC, I believe in capitalism). The problem is that unchallenged monopoly power suffocates innovation, replacing the restless drive to invent with complacency and gatekeeping that keeps fresh ideas on the sidelines. Without these incumbents’ buy-in, new entrants can’t gain access to the data they need to build better products. And because of their established market position, they stand to lose more than to gain from innovating. It's a classic innovator’s dilemma. These monopolies weren’t built for transparency, interoperability or adaptability. They were built for control. Who loses? Users and customers, who remain stuck with sub-par products that feel obsolete compared with what’s now possible.
The good news? AI-powered workflows give us the wrecking ball, finally. Through AI, it’s now possible to capture new data, at scale, in an unfathomable amount of detail, which will be used to provide 100x better products or services to end users. This is the real unlock: using AI to structure, surface, and monetize the data trapped inside opaque systems and human processes.
An Overview of Existing Data Monopolies
Before we dive into the AI-powered playbook, let’s revisit how some of the incumbents built their moats over decades. You’ll recognize most of these, and I’m certainly missing many. Their aggregate market cap? Over $600B.
{{slider-2}}
What Do Traditional Monopolies Have In Common?

I see two types of monopoly-disruptors emerging:
- Modernizers – startups that go after the same datasets the incumbents hoard (credit files, medical records, commercial listings) but deliver them faster, cheaper, and in higher resolution.
- Pioneers – teams that surface entirely new signals the market has never seen, because AI lets them observe what was previously invisible: sentiment hidden in phone calls, clause-level contract deviations, micro-movement in satellite imagery, etc. These companies don’t steal the moat—they dig an entirely new one.
Where to start?
So what does a monopoly-disruptor look like in the “AI-Native” era? The opportunity isn’t to replicate their closed systems with updated infrastructure. It’s to build embedded, AI-powered, high value workflows that generate aggregated compounding insights. These new systems don’t gatekeep; they create value through usage while expanding access to data.
- Embed deeply.
Start by choosing a standalone workflow—something customers would want to pay for on its own, and make it 10x better with AI. This is essential because only sustained usage (driven by actually valuable workflows) can generate data moats, and unique insights. - Capture passively.
As users engage, the system auto-captures structured, high-resolution data behind the scenes. For example, voice-AI claims inspections log sentiment, fraud flags, and repair timelines automatically—no extra clicks required. - Incentivize opt-in from Day 1.
Make data contribution a clear win (better outcomes, tiered pricing, premium features). Early transparency and user benefit build trust and participation over time. In the old paradigm, some of the incumbents got started by building data consortiums and data co-ops.
- Dual consumption.
Architect for your dataset to power in-product features (this is the flywheel that makes the product continuously better) and/or, to be packaged as a standalone intelligence product—for example, an underwriting API or fraud-signal feed that other market participants pay to access.
- Solve the cold-start elegantly.
- Narrow the beachhead (one segment, one geography) to reach density fast.
- Borrow or buy seed data—public filings, a niche SaaS acquisition, even paid labeling sprints.
- Stay portable—partnerships are fine, but build exit ramps so you never depend on someone else’s API.
- Narrow the beachhead (one segment, one geography) to reach density fast.
Do those five things and usage turns into proprietary signals long before the old guard finishes its next quarterly roadmap review.
What Makes a Market Ready for AI-Native Data Systems?
Not every industry lends itself to this kind of compounding data advantage. The most promising opportunities tend to share a few core characteristics:
- High velocity. Data changes rapidly (think dynamic pricing, real-time capacity, or shifting risk signals) making continuous tracking essential.
- Lots of legacy opacity. Industries that are highly “documented”, especially in unstructured ways, are a particular good fit. There, information is often siloed, outdated, or buried in manual processes. AI can surface what was previously invisible.
- Clear economic impact. The data must influence high-stakes decisions affecting revenue, cost, or risk in ways that justify investment.
- Variable cadence, but meaningful outcomes. Even lower-frequency domains (e.g., clinical trials, major M&A) can support structured data workflows if the stakes are high enough.
In short: the ideal market is one where AI can formalize the informal, turn opacity into visibility, and convert messy workflows into structured, actionable intelligence.
In theory, the incumbents could do this themselves. But in practice, most won’t. Many legacy players, especially in industries like insurance and finance, are insulated by high margins and entrenched workflows. Embedding AI would require unwinding decades of process and rethinking their entire approach to data.
Startups don’t have baggage. They can move faster, build smarter, and architect systems designed from day one to generate continuous insight.
Where AI Workflows Are Unlocking Hidden Value: Industry Deep Dives
Let’s look at a few pockets where AI-native workflows are already unlocking hidden data, transforming outdated processes, and creating real-time visibility—especially in industries that have long relied on slow, siloed systems. This list is very non-exhaustive: if you can think of others not included here, please reach out (one that I am not touching on, for example, is employment data: the disruption of LinkedIn should be its own article).
Select opportunities for AI workflow to uncover data moats
{{slider-1}}
Who Wants To Disrupt A Monopoly?
If You Want to Disrupt a Monopoly, Don’t Ask for Permission
As we move toward ever more powerful AI—and eventually AGI—algorithms and models will become widely accessible. Building products will become easier and easier. One of the only defensible advantages that remains is data (the other is trust: more on this in a future post): the unique, high-resolution signals generated by your AI workflows.
However, capturing data isn’t enough. It must be done responsibly.
Founders: build with privacy and transparency at the core, and ensure every piece of data you collect comes with a clear benefit for your users—better predictions, smoother workflows, or richer insights. When your product genuinely improves someone’s day-to-day work, they’ll gladly contribute the data that fuels your advantage.
The next generation of leaders won’t just build better AI. They’ll create new data empires by unlocking what’s been hidden for decades. They’ll find value in workflows that incumbents ignore. And they’ll do it responsibly, with user trust at the center.
If you’re a founder looking to build something enduring, don’t wait for permission. Use AI to reveal what’s hidden, capture what’s overlooked, and create clarity where others still see noise. That’s the real advantage. And it compounds.